
This post represents the second and final chapter from last week’s post, “Machine Learning Leveraging New Actionable Data From Erasure Qubit Quantum Computers.”
Running a more complex algorithm on the Aqumen Seeker QPU, like Grover’s search, opens up a fascinating landscape of features and patterns in the error detected data. The algorithm is far more complex than the Bernstein-Vazirani (BV) example, with hundreds more single and two-qubit gates when run with just five qubits, and is much more than a toy demonstration but something that has real-world implications if run successfully at scale.
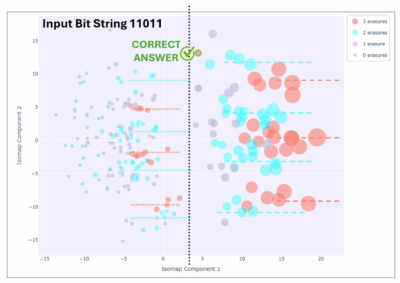
Figure 3 shows the isomap for the results, from 0 erasures to 3 erasures all plotted together. A number of unique features stand out immediately.
The first is that the correct answer is still visible, matching the input bit string of 11011 in this example. Although not as prominent as in the case of BV, the counts in that green circle exceed those of any other green circle by an order of magnitude. They are, of course, dominated by the counts in the detected erasures, shown in purple, cyan and red. However, this again underscores the power of error detection in picking out the correct answer when enough data is present (in this case, 1,000,000 shots, which were acquired quickly on our superconducting system).
Second, unlike in BV, and certainly unlike the conventional superconducting QPU case, the data shows a rich structure to it. The case of three erasures (red) is grouped in three clear stripes, accentuated by the dotted lines. The two-erasure case is grouped into four clear stripes, highlighted by the four cyan dotted lines. There is a “valley” with few data counts altogether, separating the majority of the data on the right, and the remaining data on the left, where the latter continues to loosely follow a similar striped pattern.
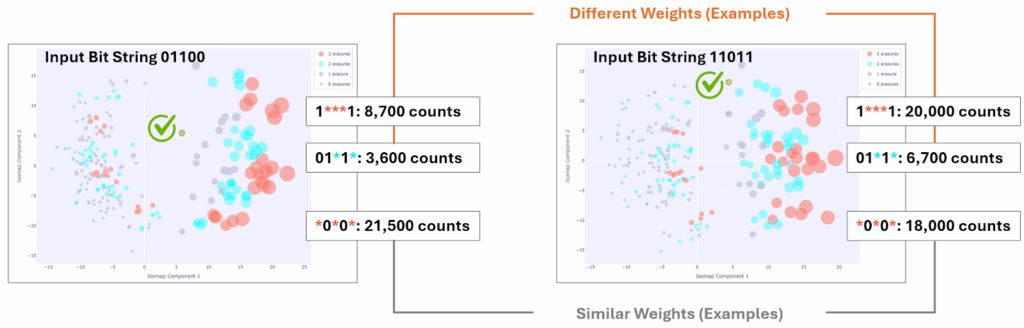
Third, and perhaps most intriguing, is that although different input bit strings return similar looking patterns, the counts obtained within each circle in the isomap are different. Figure 4 shows an example. Patterns 01100 and 11011 are compared side-by-side. The patterns are similar. However, in each of these cases, the different circles in the detected erasure cases (purple, cyan, red circles) have different counts. For example, the pattern 1***1 was measured 8,700 times for the input string 01100, while the same pattern was measured 20,000 times for an input string of 11011. There is more information in the isomap than just the pattern!
We now get to the supervised ML part. There are many directions we can take this. Here we’ll motivate two forward-looking ones that can unlock a diverse landscape of algorithm exploration coupling near-term quantum computing and advanced classical data processing.
First, we can begin implementing a supervised ML model where the inputs are all 32 combinations of Grover input bit strings. Each Grover isomap has a similar visual pattern to it but is nonetheless slightly different. This is akin to classifying 32 images of cats, which would all be different, but still share common features that an ML model can learn.
With the 32 examples of Grover in-hand, we would feed this to the supervised ML model so it would learn what “Grover” looks like as far as a pattern on an isomap. To be sure, we would like more than 32 inputs, so this is a small example. However, the inputs will grow exponentially with qubit number. For example, with just 20 qubits, you have over one million samples.
Such classification could be valuable to help identify patterns in other algorithms, which may exhibit properties similar to Grover and provide insight as to their execution flow or error properties. This can of course be generalized beyond Grover to any kind of algorithm, and in particular it will be interesting to inspect how patterns evolve for applications where ideal results are non-deterministic, such as iterative algorithms like VQE or QAOA.
A second possible direction is building a model that starts to identify the relationships between input bit strings and the erasure counts associated with them. We can leverage this new information for some new level of predictive gain. For example, we may gain insight into expected correct answers in regimes where erasures are dominating, simply based on the patterns we are observing. This is possible because error detection – and the availability of new high-quality data – enables the kind of unique patterns and correlations that aren’t possible in systems where silent errors are the primary source of decoherence.
What we’re highlighting here is the information encoded in the output data contains valuable insight that could lead to newly understood dynamics of qubit evolution over the course of the algorithm. ML therefore is a valuable tool that can provide a level of training on smaller scale data when error-free trajectories are still strong enough to extract meaningful information from a data set too noisy to analyze otherwise.
We’re excited to share these insights, as they’re hot off the press. We will, of course, continue to follow the promising lines of research identified above. However, we are even more excited about what users will uncover when getting their hands on our simulators and DRQ-based QPUs.
We see the addition of error-detected data as a transformative enhancement to quantum computing workflows, which will lead to new classes of applications and synergies with advanced classical processing.It motivates in a concrete way how the new high-quality data returned by Quantum Circuits’ DRQ-based systems can yield insights into the facets of a QPU and quantum algorithm that wouldn’t have been available before.
The availability of more data and the tools with which to analyze it takes us beyond NISQ. While error correction and fault tolerance work in our hardware efficient approach is still underway, exploiting near-term systems to explore a new class of algorithms, previously inaccessible, is incredibly exciting. We’re looking forward to making all of these tools available to users to discover what error detection can yield, while we continue on our trajectory to release the most unique and efficient quantum systems in the industry.
Please reach out to us if you’re interested in exploring the intersection between AI, ML and quantum with DRQs. We’re excited about the momentum that’s building in these fields and learning more from users across all industries.

